

High availability design demi uptime aplikasi bisnis mendekati 100% – Dalam dunia bisnis digital yang serba cepat, ketersediaan aplikasi adalah kunci utama. Bayangkan, aplikasi bisnis Anda selalu aktif, selalu dapat diakses, dan selalu siap melayani pelanggan. Inilah esensi dari High Availability Design, sebuah pendekatan yang dirancang untuk memastikan uptime aplikasi bisnis mendekati 100%.
Topik ini akan membahas secara mendalam tentang bagaimana merancang, mengimplementasikan, dan mengelola sistem yang andal dan tahan terhadap kegagalan. Kita akan menjelajahi berbagai komponen kunci, prinsip desain, arsitektur, teknologi pendukung, serta prosedur operasional yang diperlukan untuk mencapai tujuan tersebut. Tak hanya itu, studi kasus nyata akan memberikan gambaran jelas tentang dampak positifnya terhadap bisnis.
Pengantar Desain Ketersediaan Tinggi (High Availability)
Dalam dunia bisnis yang digerakkan oleh teknologi, ketersediaan aplikasi menjadi kunci utama. Bayangkan sebuah aplikasi yang selalu dapat diakses, tanpa gangguan, memberikan pengalaman pengguna yang mulus, dan mendukung operasi bisnis tanpa henti. Inilah esensi dari desain ketersediaan tinggi (High Availability/HA), sebuah pendekatan strategis yang dirancang untuk memastikan aplikasi bisnis tetap beroperasi dengan uptime mendekati 100%.
Desain HA bukan hanya tentang membuat aplikasi ‘hidup’ terus menerus, tetapi juga tentang menciptakan sistem yang tangguh terhadap berbagai kegagalan, mulai dari gangguan perangkat keras hingga lonjakan lalu lintas yang tak terduga. Dengan merancang sistem yang mampu secara otomatis pulih dari masalah, bisnis dapat meminimalkan dampak negatif dari downtime, seperti hilangnya pendapatan, kerusakan reputasi, dan hilangnya kepercayaan pelanggan.
Konsep Dasar Desain Ketersediaan Tinggi dan Relevansinya
Desain ketersediaan tinggi berfokus pada penyediaan layanan yang berkelanjutan dengan meminimalkan waktu henti (downtime). Ini dicapai melalui redundansi, failover otomatis, dan pemantauan proaktif. Redundansi berarti memiliki lebih dari satu komponen untuk setiap fungsi penting, sehingga jika satu komponen gagal, komponen lain dapat segera mengambil alih. Failover otomatis memastikan bahwa sistem secara otomatis beralih ke komponen cadangan tanpa intervensi manual. Pemantauan proaktif melibatkan pengawasan terus-menerus terhadap sistem untuk mendeteksi potensi masalah sebelum mereka menyebabkan gangguan.
Relevansi desain HA untuk aplikasi bisnis sangat besar. Aplikasi bisnis yang kritis, seperti sistem e-commerce, perbankan online, dan platform komunikasi, harus selalu tersedia untuk melayani pelanggan dan memproses transaksi. Downtime bahkan dalam hitungan menit dapat mengakibatkan kerugian finansial yang signifikan dan merusak reputasi perusahaan. Desain HA memastikan bahwa aplikasi ini tetap beroperasi, bahkan dalam menghadapi kegagalan.
Manfaat Utama Menerapkan Desain Ketersediaan Tinggi
Menerapkan desain ketersediaan tinggi memberikan sejumlah manfaat utama bagi bisnis:
- Peningkatan Uptime: Uptime mendekati 100% berarti aplikasi selalu tersedia, memastikan kelangsungan bisnis dan kepuasan pelanggan.
- Minimasi Downtime: Redundansi dan failover otomatis mengurangi waktu henti yang disebabkan oleh kegagalan perangkat keras, perangkat lunak, atau jaringan.
- Peningkatan Produktivitas: Karyawan dapat terus bekerja tanpa gangguan, meningkatkan produktivitas dan efisiensi operasional.
- Peningkatan Kepuasan Pelanggan: Ketersediaan aplikasi yang konsisten meningkatkan pengalaman pelanggan, memperkuat loyalitas, dan meningkatkan citra merek.
- Pengurangan Kerugian Finansial: Downtime yang berkurang secara langsung mengurangi hilangnya pendapatan, biaya pemulihan, dan potensi denda akibat pelanggaran layanan.
- Peningkatan Kepercayaan Bisnis: Sistem yang andal membangun kepercayaan dengan pelanggan, mitra, dan pemangku kepentingan lainnya.
Mengapa Uptime Aplikasi Mendekati 100% Sangat Krusial
Uptime aplikasi yang mendekati 100% sangat penting untuk kelangsungan bisnis karena beberapa alasan utama:
- Dampak Finansial: Downtime dapat mengakibatkan hilangnya pendapatan langsung, biaya pemulihan, dan potensi denda atau penalti. Contohnya, downtime pada platform e-commerce selama periode puncak penjualan dapat menyebabkan kerugian jutaan rupiah.
- Dampak Reputasi: Downtime dapat merusak reputasi perusahaan, menyebabkan hilangnya kepercayaan pelanggan, dan berdampak negatif pada citra merek. Pelanggan cenderung beralih ke pesaing jika aplikasi tidak dapat diakses.
- Dampak Operasional: Downtime dapat mengganggu operasi bisnis, menghambat produktivitas karyawan, dan memperlambat proses bisnis penting. Contohnya, downtime pada sistem manajemen inventaris dapat menghentikan pengiriman pesanan.
- Dampak Kompetitif: Dalam lingkungan bisnis yang kompetitif, uptime yang tinggi adalah keunggulan kompetitif. Bisnis yang dapat menyediakan layanan yang andal dan selalu tersedia memiliki keunggulan dibandingkan pesaing yang mengalami downtime.
Perbandingan Sederhana Aplikasi dengan dan Tanpa Desain Ketersediaan Tinggi
Perbedaan antara aplikasi dengan dan tanpa desain ketersediaan tinggi sangat signifikan, terutama dalam hal pengalaman pengguna:
| Fitur | Aplikasi Tanpa HA | Aplikasi Dengan HA |
|---|---|---|
| Ketersediaan | Rentan terhadap downtime akibat kegagalan. | Selalu tersedia, dengan downtime minimal. |
| Respons Terhadap Kegagalan | Downtime berkepanjangan, membutuhkan intervensi manual untuk pemulihan. | Failover otomatis, pemulihan cepat tanpa intervensi pengguna. |
| Pengalaman Pengguna | Pengguna mengalami gangguan, frustrasi, dan potensi kehilangan data. | Pengguna mengalami pengalaman yang mulus dan konsisten. |
| Dampak Bisnis | Potensi hilangnya pendapatan, kerusakan reputasi, dan hilangnya pelanggan. | Kelangsungan bisnis, peningkatan kepuasan pelanggan, dan peningkatan citra merek. |
Contohnya, bayangkan sebuah bank online. Aplikasi tanpa HA mungkin mengalami downtime selama beberapa jam jika server utama mengalami masalah. Nasabah tidak dapat mengakses rekening mereka, melakukan transaksi, atau membayar tagihan. Sebaliknya, aplikasi dengan HA akan secara otomatis beralih ke server cadangan, memastikan nasabah dapat terus menggunakan layanan tanpa gangguan.
Tantangan Umum dalam Mencapai Ketersediaan Tinggi dan Solusinya
Mencapai ketersediaan tinggi bukanlah hal yang mudah dan melibatkan beberapa tantangan umum:
- Kegagalan Perangkat Keras: Server, penyimpanan, dan jaringan dapat mengalami kegagalan.
- Kegagalan Perangkat Lunak: Bug, kesalahan konfigurasi, dan serangan siber dapat menyebabkan downtime.
- Gangguan Jaringan: Masalah konektivitas dapat memutus akses ke aplikasi.
- Beban Kerja yang Tinggi: Lonjakan lalu lintas dapat membebani sistem dan menyebabkan kinerja yang buruk.
Desain ketersediaan tinggi membantu mengatasi tantangan ini melalui:
- Redundansi: Memiliki cadangan untuk semua komponen penting.
- Failover Otomatis: Sistem secara otomatis beralih ke komponen cadangan saat terjadi kegagalan.
- Pemantauan Proaktif: Memantau sistem secara terus-menerus untuk mendeteksi potensi masalah.
- Penskalaan Otomatis: Menyesuaikan sumber daya secara dinamis untuk menangani beban kerja yang berubah.
- Distribusi Geografis: Menyebarkan aplikasi di beberapa lokasi untuk melindungi dari bencana regional.
Komponen Kunci dalam Desain Ketersediaan Tinggi
Desain ketersediaan tinggi (High Availability/HA) merupakan fondasi penting bagi aplikasi bisnis yang membutuhkan uptime mendekati 100%. Untuk mencapai hal ini, diperlukan pemahaman mendalam tentang komponen-komponen kunci yang saling bekerja sama untuk memastikan aplikasi tetap berfungsi, bahkan saat terjadi kegagalan. Mari kita telaah komponen-komponen krusial tersebut.
Redundansi: Mencegah Kegagalan Tunggal
Redundansi adalah prinsip dasar dalam desain HA, yang berarti memiliki lebih dari satu komponen untuk setiap fungsi penting. Tujuannya adalah untuk menghilangkan single point of failure (SPOF), yaitu komponen tunggal yang jika gagal akan menyebabkan seluruh sistem berhenti berfungsi. Dengan redundansi, jika satu komponen gagal, komponen lain yang identik akan segera mengambil alih tugasnya tanpa gangguan berarti.
- Server Redundansi: Memiliki beberapa server yang menjalankan aplikasi yang sama. Jika satu server gagal, server lain akan tetap beroperasi.
- Redundansi Jaringan: Menggunakan beberapa jalur jaringan (misalnya, dua router atau switch) untuk memastikan konektivitas tetap terjaga jika salah satu jalur gagal.
- Redundansi Penyimpanan: Menggunakan sistem penyimpanan yang memiliki redundansi (misalnya, RAID) untuk melindungi data dari kehilangan jika ada kegagalan pada hard drive.
- Redundansi Daya: Menggunakan Uninterruptible Power Supply (UPS) atau generator cadangan untuk memastikan pasokan listrik yang stabil, bahkan saat terjadi pemadaman listrik.
Failover: Mekanisme Pengalihan Otomatis
Failover adalah proses otomatis di mana sistem secara otomatis mengalihkan tugas dari komponen yang gagal ke komponen cadangan. Proses ini harus cepat dan transparan bagi pengguna akhir. Berikut adalah ilustrasi bagaimana failover bekerja dalam situasi kegagalan server:
Ilustrasi Failover Server:
- Kondisi Awal: Terdapat dua server (Server Utama dan Server Cadangan) yang menjalankan aplikasi. Server Utama aktif dan melayani permintaan pengguna. Server Cadangan dalam keadaan standby, siap mengambil alih jika diperlukan.
- Deteksi Kegagalan: Sistem pemantauan (monitoring system) terus-menerus memantau kesehatan Server Utama. Jika sistem mendeteksi kegagalan (misalnya, server tidak responsif atau layanan berhenti), proses failover dimulai.
- Pengalihan Otomatis: Sistem secara otomatis mengalihkan lalu lintas dari Server Utama ke Server Cadangan. Proses ini melibatkan perubahan konfigurasi jaringan (misalnya, mengubah alamat IP atau DNS) agar permintaan pengguna diarahkan ke Server Cadangan.
- Aktivasi Server Cadangan: Server Cadangan, yang sebelumnya dalam keadaan standby, sekarang menjadi server aktif dan mulai melayani permintaan pengguna. Proses ini sering kali melibatkan sinkronisasi data terbaru dari server utama (sebelum kegagalan) ke server cadangan.
- Pemulihan (Opsional): Setelah Server Utama diperbaiki, sistem dapat dikonfigurasi untuk mengembalikan lalu lintas ke Server Utama (failback), atau membiarkannya tetap di Server Cadangan, tergantung pada konfigurasi yang diinginkan.
Load Balancing: Mendistribusikan Beban Kerja
Load balancing adalah proses mendistribusikan beban kerja (misalnya, permintaan pengguna) ke beberapa sumber daya (misalnya, server) untuk memastikan tidak ada satu pun sumber daya yang kelebihan beban. Hal ini meningkatkan kinerja aplikasi dan ketersediaan, karena jika satu server mengalami masalah, lalu lintas secara otomatis dialihkan ke server yang sehat.
Berikut adalah tabel yang membandingkan beberapa metode load balancing:
| Metode | Keterangan | Kelebihan | Kekurangan |
|---|---|---|---|
| Round Robin | Permintaan didistribusikan secara bergantian ke setiap server dalam urutan. | Sederhana untuk diimplementasikan; cocok untuk lingkungan yang sederhana. | Tidak mempertimbangkan kapasitas atau beban server; dapat menyebabkan ketidakseimbangan jika server memiliki spesifikasi yang berbeda. |
| Least Connections | Permintaan diarahkan ke server dengan koneksi aktif paling sedikit. | Mempertimbangkan beban server; lebih efektif untuk aplikasi yang memiliki koneksi yang bervariasi. | Membutuhkan pemantauan koneksi yang berkelanjutan; sedikit lebih kompleks untuk dikonfigurasi. |
| IP Hash | Permintaan dari alamat IP klien yang sama selalu diarahkan ke server yang sama. | Memastikan sesi pengguna tetap konsisten (session persistence); berguna untuk aplikasi yang membutuhkan penyimpanan sesi. | Rentang terhadap kegagalan server; jika server gagal, semua sesi pengguna yang terhubung ke server tersebut akan terputus. |
Contoh Skenario Load Balancing
Pertimbangkan sebuah aplikasi e-commerce yang memiliki lonjakan lalu lintas selama periode promosi. Tanpa load balancing, satu server tunggal akan kewalahan, mengakibatkan waktu respons yang lambat atau bahkan kegagalan aplikasi. Dengan load balancing, permintaan pengguna didistribusikan ke beberapa server yang menjalankan aplikasi e-commerce tersebut. Jika salah satu server mengalami masalah, load balancer secara otomatis mengalihkan lalu lintas ke server yang sehat. Hal ini memastikan bahwa pengguna tetap dapat mengakses aplikasi, melakukan pembelian, dan pengalaman pengguna tetap terjaga, bahkan selama periode lalu lintas tinggi.
Prinsip Desain untuk Uptime Maksimal
Mencapai uptime aplikasi bisnis mendekati 100% bukanlah sebuah kebetulan, melainkan hasil dari perencanaan yang matang dan implementasi prinsip-prinsip desain yang tepat. Fokus utama adalah mengeliminasi potensi kegagalan, memantau kinerja secara terus-menerus, dan mengotomatisasi sebanyak mungkin proses untuk memastikan aplikasi selalu tersedia. Mari kita bedah prinsip-prinsip tersebut beserta contoh penerapannya.
Menghilangkan Single Point of Failure (SPoF)
Salah satu fondasi utama dalam desain ketersediaan tinggi adalah menghilangkan titik-titik kegagalan tunggal. SPoF adalah komponen dalam sistem yang, jika gagal, akan menyebabkan seluruh sistem gagal. Pendekatan ini melibatkan redundansi, yaitu memiliki lebih dari satu komponen yang melakukan fungsi yang sama, sehingga jika satu komponen gagal, komponen lain dapat mengambil alih tanpa gangguan layanan.
- Redundansi pada Tingkat Perangkat Keras: Contohnya, penggunaan server ganda (atau lebih) dalam konfigurasi aktif-pasif atau aktif-aktif. Jika server aktif mengalami masalah, server pasif akan mengambil alih secara otomatis. Implementasi ini juga berlaku untuk perangkat jaringan seperti router dan switch.
- Redundansi pada Tingkat Perangkat Lunak: Menggunakan database cluster, di mana data direplikasi di beberapa server database. Jika salah satu server database down, aplikasi tetap dapat mengakses data dari server lainnya.
- Load Balancing: Mendistribusikan lalu lintas (traffic) ke beberapa server. Load balancer akan mendeteksi server yang tidak responsif dan mengarahkan permintaan ke server yang sehat.
Monitoring, Alerting, dan Otomatisasi
Pemantauan yang komprehensif, sistem peringatan yang responsif, dan otomatisasi adalah kunci untuk menjaga ketersediaan tinggi. Pemantauan memungkinkan deteksi dini masalah, sementara peringatan memastikan tim operasi segera mendapatkan informasi. Otomatisasi mengurangi waktu respons dan meminimalkan intervensi manual.
- Pemantauan Proaktif: Implementasikan sistem pemantauan yang memantau berbagai aspek aplikasi, termasuk kinerja server, penggunaan memori, waktu respons aplikasi, dan status layanan. Gunakan tools seperti Prometheus, Grafana, atau solusi monitoring dari penyedia cloud seperti AWS CloudWatch atau Azure Monitor.
- Peringatan (Alerting): Atur ambang batas (threshold) untuk metrik penting. Ketika ambang batas terlampaui, sistem akan mengirimkan peringatan (alert) melalui email, SMS, atau platform kolaborasi seperti Slack atau Microsoft Teams. Penting untuk memprioritaskan peringatan berdasarkan tingkat keparahan.
- Otomatisasi Respon: Otomatisasi dapat digunakan untuk menangani masalah secara otomatis. Contohnya, jika server mencapai penggunaan CPU yang tinggi, sistem dapat secara otomatis menskalakan sumber daya (scaling) dengan menambahkan instance server baru. Otomatisasi juga dapat digunakan untuk memulihkan layanan yang gagal.
Pemilihan Teknologi dan Infrastruktur
Pilihan teknologi dan infrastruktur yang tepat sangat penting untuk mendukung ketersediaan tinggi. Pertimbangkan aspek-aspek berikut dalam proses seleksi.
- Penyedia Layanan Cloud: Platform cloud seperti AWS, Azure, dan Google Cloud menawarkan berbagai layanan yang dirancang untuk ketersediaan tinggi, termasuk layanan komputasi, penyimpanan, database, dan jaringan. Manfaatkan fitur-fitur seperti Availability Zones, Load Balancer, dan Auto Scaling.
- Database: Pilih sistem database yang mendukung replikasi dan clustering. Contohnya, PostgreSQL dengan streaming replication, MySQL Cluster, atau database NoSQL seperti Cassandra.
- Caching: Gunakan caching untuk mengurangi beban pada database dan meningkatkan waktu respons aplikasi. Tools caching populer meliputi Redis dan Memcached.
- Content Delivery Network (CDN): Jika aplikasi Anda melayani konten statis, gunakan CDN untuk mendistribusikan konten ke lokasi geografis yang berbeda, sehingga pengguna mendapatkan akses yang lebih cepat dan mengurangi beban pada server asal.
Pentingnya Monitoring dan Logging
Monitoring dan logging adalah dua pilar penting dalam desain ketersediaan tinggi. Keduanya bekerja secara sinergis untuk memberikan visibilitas ke dalam kinerja dan perilaku aplikasi, memungkinkan deteksi dini masalah dan penyelesaian yang cepat.
- Monitoring: Seperti yang telah dijelaskan sebelumnya, monitoring memantau metrik kinerja dan kesehatan aplikasi secara real-time. Ini termasuk metrik server (CPU, memori, disk I/O), metrik aplikasi (waktu respons, jumlah transaksi), dan metrik jaringan (latency, throughput).
- Logging: Logging mencatat peristiwa yang terjadi dalam aplikasi, termasuk kesalahan (errors), peringatan (warnings), dan informasi (information). Log menyediakan jejak audit yang berharga untuk memecahkan masalah, menganalisis perilaku aplikasi, dan mengidentifikasi tren. Pastikan log mencakup informasi yang cukup detail untuk memungkinkan analisis yang efektif, termasuk timestamp, ID transaksi, dan informasi kontekstual lainnya.
- Centralized Logging: Kumpulkan log dari berbagai sumber (server, aplikasi, database) ke dalam sistem terpusat seperti ELK Stack (Elasticsearch, Logstash, Kibana) atau Splunk. Ini memudahkan pencarian, analisis, dan visualisasi log.
- Alerting Berbasis Log: Atur peringatan berdasarkan pola yang terdeteksi dalam log. Misalnya, jika ada banyak pesan error yang terkait dengan koneksi database, sistem dapat mengirimkan peringatan.
Panduan Singkat Desain Ketersediaan Tinggi:
- Hilangkan SPoF: Gunakan redundansi pada semua tingkatan (perangkat keras, perangkat lunak, jaringan).
- Implementasikan Monitoring: Pantau semua aspek aplikasi secara real-time.
- Siapkan Alerting: Definisikan ambang batas dan atur peringatan yang relevan.
- Otomatisasi: Otomatisasi respons terhadap masalah.
- Pilih Teknologi yang Tepat: Manfaatkan layanan cloud, database yang andal, caching, dan CDN.
- Centralized Logging: Kumpulkan dan analisis log secara terpusat.
Arsitektur dan Teknologi Pendukung: High Availability Design Demi Uptime Aplikasi Bisnis Mendekati 100%
Untuk mencapai ketersediaan tinggi dan uptime mendekati 100% pada aplikasi bisnis, pemilihan arsitektur dan teknologi pendukung yang tepat sangat krusial. Keputusan ini akan memengaruhi bagaimana aplikasi dapat terus berfungsi, bahkan ketika terjadi kegagalan pada komponen tertentu. Berikut ini akan dibahas berbagai arsitektur dan teknologi yang umum digunakan, beserta kelebihan dan kekurangannya.
Arsitektur Ketersediaan Tinggi
Beberapa arsitektur yang sering digunakan dalam desain ketersediaan tinggi memiliki karakteristik dan implementasi yang berbeda. Pemahaman mendalam tentang arsitektur ini membantu dalam memilih solusi yang paling sesuai dengan kebutuhan spesifik aplikasi.
- Active-Active: Pada arsitektur ini, semua instance aplikasi (server) aktif dan melayani traffic secara bersamaan. Beban kerja didistribusikan di antara semua instance, sehingga meningkatkan kapasitas dan ketersediaan. Jika salah satu instance gagal, instance lain dapat melanjutkan melayani traffic tanpa gangguan.
- Kelebihan:
- Peningkatan kapasitas dan performa karena beban kerja didistribusikan.
- Tidak ada waktu henti (downtime) saat terjadi kegagalan, karena semua instance aktif.
- Kekurangan:
- Membutuhkan sinkronisasi data yang kompleks jika aplikasi menyimpan data.
- Membutuhkan load balancer untuk mendistribusikan traffic secara merata.
- Lebih mahal karena membutuhkan lebih banyak sumber daya.
- Kelebihan:
- Active-Passive: Dalam arsitektur ini, hanya satu instance aplikasi yang aktif dan melayani traffic. Instance lainnya (pasif) dalam keadaan siaga dan siap menggantikan instance aktif jika terjadi kegagalan.
- Kelebihan:
- Lebih sederhana dan lebih mudah diimplementasikan dibandingkan active-active.
- Lebih hemat biaya karena hanya membutuhkan sumber daya yang lebih sedikit.
- Kekurangan:
- Terdapat potensi waktu henti (downtime) saat terjadi kegagalan, meskipun relatif singkat.
- Kapasitas dan performa tidak meningkat, karena hanya satu instance yang aktif.
- Kelebihan:
- N-Tier Architecture: Arsitektur ini membagi aplikasi menjadi beberapa lapisan (tiers) yang berbeda, seperti lapisan presentasi (presentation tier), lapisan aplikasi (application tier), dan lapisan data (data tier). Setiap lapisan dapat memiliki ketersediaan tinggi dengan menggunakan arsitektur active-active atau active-passive.
- Kelebihan:
- Memudahkan pengelolaan dan pemeliharaan aplikasi.
- Memungkinkan penskalaan yang lebih fleksibel pada setiap lapisan.
- Kekurangan:
- Lebih kompleks dalam implementasi.
- Membutuhkan koordinasi yang baik antar lapisan.
- Kelebihan:
Teknologi Pendukung Implementasi Ketersediaan Tinggi
Berbagai teknologi dapat diintegrasikan untuk mendukung implementasi desain ketersediaan tinggi. Pemilihan teknologi yang tepat bergantung pada kebutuhan spesifik aplikasi dan arsitektur yang digunakan.
- Database Clustering: Teknologi ini memungkinkan beberapa server database bekerja bersama sebagai satu unit, menyediakan redundansi dan failover. Jika salah satu server database gagal, server lain dapat mengambil alih, memastikan data tetap tersedia.
- Content Delivery Network (CDN): CDN mendistribusikan konten statis (gambar, video, CSS, JavaScript) ke server di berbagai lokasi geografis. Pengguna mendapatkan konten dari server yang terdekat, mengurangi latensi dan meningkatkan performa. CDN juga dapat menangani lonjakan traffic dan melindungi aplikasi dari serangan DDoS.
- Load Balancer: Load balancer mendistribusikan traffic masuk ke beberapa server aplikasi. Hal ini meningkatkan ketersediaan dan performa, serta memungkinkan penskalaan aplikasi. Load balancer juga dapat melakukan pemeriksaan kesehatan (health checks) untuk memastikan hanya server yang sehat yang menerima traffic.
Database Clustering: Perbandingan Fitur
Berbagai jenis database clustering memiliki fitur yang berbeda. Pemilihan jenis clustering yang tepat bergantung pada kebutuhan spesifik aplikasi, seperti kebutuhan akan konsistensi data, skalabilitas, dan kompleksitas implementasi.
| Jenis Clustering | Fitur Utama | Kelebihan | Kekurangan |
|---|---|---|---|
| Active-Active Clustering | Semua node aktif dan melayani traffic. Sinkronisasi data real-time. | Peningkatan performa dan ketersediaan tinggi. Tidak ada downtime saat failover. | Kompleksitas tinggi. Membutuhkan sinkronisasi data yang intensif. |
| Active-Passive Clustering | Satu node aktif, sisanya pasif (siaga). Failover otomatis. | Implementasi lebih sederhana. Lebih hemat biaya. | Potensi downtime saat failover (meskipun singkat). |
| Master-Slave Replication | Satu node master menerima write, node slave menerima read. Replikasi data asinkron atau sinkron. | Peningkatan performa read. Mudah diimplementasikan. | Tidak cocok untuk write yang intensif. Potensi kehilangan data pada replikasi asinkron. |
| Sharding | Data dibagi menjadi beberapa shard (partisi) yang disimpan di berbagai server. | Skalabilitas horizontal yang tinggi. Peningkatan performa. | Kompleksitas manajemen data. Membutuhkan perencanaan yang matang. |
Ilustrasi CDN Meningkatkan Ketersediaan dan Performa Aplikasi
Ilustrasi berikut menggambarkan bagaimana CDN meningkatkan ketersediaan dan performa aplikasi:
Bayangkan sebuah aplikasi e-commerce yang melayani pengguna di seluruh dunia. Tanpa CDN, semua pengguna harus mengakses server pusat yang berlokasi di satu tempat. Hal ini menyebabkan latensi tinggi bagi pengguna yang jauh dari server, terutama saat mengakses gambar produk dan konten statis lainnya. Jika server pusat mengalami masalah, seluruh aplikasi akan mengalami downtime.
Dengan menggunakan CDN, konten statis aplikasi (gambar, video, CSS, JavaScript) diduplikasi dan didistribusikan ke berbagai server di seluruh dunia. Ketika pengguna mengakses aplikasi, mereka mendapatkan konten dari server CDN terdekat. Hal ini mengurangi latensi secara signifikan, karena data dikirimkan lebih cepat. Jika server CDN di suatu lokasi mengalami masalah, pengguna tetap dapat mengakses konten dari server CDN lain. Selain itu, CDN dapat menangani lonjakan traffic dan melindungi aplikasi dari serangan DDoS, sehingga meningkatkan ketersediaan aplikasi.
Prosedur dan Operasional

Memastikan aplikasi bisnis beroperasi dengan ketersediaan tinggi bukan hanya tentang desain infrastruktur yang canggih, tetapi juga tentang prosedur operasional yang solid dan terencana. Hal ini mencakup serangkaian langkah yang terstruktur untuk mengelola, memelihara, dan merespons situasi darurat. Penerapan prosedur yang tepat dan pengujian yang konsisten adalah kunci untuk menjaga aplikasi tetap berjalan, bahkan di tengah tantangan.
Prosedur Pengelolaan dan Pemeliharaan Aplikasi
Pengelolaan dan pemeliharaan aplikasi dengan ketersediaan tinggi memerlukan pendekatan yang proaktif dan terstruktur. Ini melibatkan beberapa aspek penting untuk memastikan kelancaran operasional dan respons yang cepat terhadap masalah.
- Pemantauan Proaktif: Implementasikan sistem pemantauan yang komprehensif untuk melacak kinerja aplikasi, sumber daya server, dan metrik penting lainnya. Gunakan alat seperti Prometheus, Grafana, atau Nagios untuk memvisualisasikan data dan mendapatkan peringatan dini jika terjadi anomali.
- Manajemen Insiden: Siapkan prosedur manajemen insiden yang jelas dan terdokumentasi. Prosedur ini harus mencakup langkah-langkah untuk mengidentifikasi, melaporkan, menyelidiki, dan menyelesaikan insiden dengan cepat. Pastikan tim memiliki peran dan tanggung jawab yang jelas.
- Manajemen Perubahan: Terapkan proses manajemen perubahan yang ketat untuk semua perubahan konfigurasi, pembaruan kode, dan penyesuaian infrastruktur. Proses ini harus mencakup persetujuan, pengujian, dan rencana rollback jika terjadi masalah.
- Pemulihan Bencana: Buat dan uji rencana pemulihan bencana (DRP) secara berkala. DRP harus mencakup langkah-langkah untuk memulihkan aplikasi dari kegagalan yang signifikan, seperti bencana alam atau serangan siber. Pastikan data dicadangkan secara teratur dan dapat dipulihkan dengan cepat.
- Dokumentasi: Jaga dokumentasi yang lengkap dan terkini untuk semua aspek aplikasi, termasuk arsitektur, konfigurasi, prosedur operasional, dan kontak darurat. Dokumentasi yang baik mempermudah troubleshooting dan transfer pengetahuan antar tim.
Pentingnya Pengujian dan Simulasi Kegagalan
Pengujian dan simulasi kegagalan adalah elemen krusial dalam menjaga ketersediaan aplikasi. Praktik ini membantu mengidentifikasi potensi masalah sebelum berdampak pada pengguna, serta memastikan bahwa sistem dapat merespons dengan benar dalam situasi darurat.
- Pengujian Unit: Uji setiap unit kode secara terpisah untuk memastikan fungsionalitasnya.
- Pengujian Integrasi: Uji bagaimana berbagai komponen aplikasi berinteraksi satu sama lain.
- Pengujian Beban (Load Testing): Simulasikan lalu lintas pengguna yang tinggi untuk menguji kinerja aplikasi di bawah tekanan.
- Pengujian Penetrasi (Penetration Testing): Lakukan pengujian keamanan untuk mengidentifikasi kerentanan dan potensi eksploitasi.
- Simulasi Kegagalan: Lakukan simulasi kegagalan, seperti mematikan server, memutus koneksi jaringan, atau mengganggu layanan basis data, untuk menguji kemampuan failover dan pemulihan aplikasi.
- Uji Coba Failover: Lakukan uji coba failover secara berkala untuk memastikan bahwa sistem dapat beralih ke sumber daya cadangan dengan cepat dan tanpa gangguan.
Pembaruan dan Perubahan Konfigurasi Tanpa Gangguan
Melakukan pembaruan dan perubahan konfigurasi tanpa mengganggu layanan merupakan tantangan penting dalam menjaga ketersediaan tinggi. Pendekatan yang tepat dapat meminimalkan dampak pada pengguna dan memastikan kelancaran operasional.
- Rolling Updates: Terapkan strategi rolling updates, di mana pembaruan dilakukan pada satu set server pada satu waktu, sementara server lainnya tetap melayani lalu lintas. Hal ini memastikan bahwa selalu ada server yang tersedia untuk menangani permintaan.
- Blue/Green Deployment: Gunakan metode blue/green deployment, di mana versi baru aplikasi (green) di-deploy secara paralel dengan versi yang ada (blue). Setelah pengujian selesai, lalu lintas dialihkan ke versi baru. Jika ada masalah, lalu lintas dapat dengan cepat dikembalikan ke versi lama.
- Configuration Management Tools: Gunakan alat manajemen konfigurasi seperti Ansible, Chef, atau Puppet untuk mengotomatisasi perubahan konfigurasi dan memastikan konsistensi di seluruh lingkungan.
- Canary Releases: Rilis versi baru aplikasi ke sebagian kecil pengguna (canary) untuk menguji stabilitas dan kinerja sebelum merilisnya ke semua pengguna.
- Feature Flags: Gunakan feature flags untuk mengaktifkan atau menonaktifkan fitur tertentu tanpa harus melakukan deployment ulang. Ini memungkinkan untuk mengontrol rilis fitur dan meminimalkan risiko.
- Monitoring dan Alerting: Pastikan ada sistem monitoring yang baik untuk memantau kinerja aplikasi selama dan setelah pembaruan. Siapkan alert untuk mendeteksi masalah dengan cepat.
Penggunaan Alat Monitoring untuk Pemantauan Real-time, High availability design demi uptime aplikasi bisnis mendekati 100%
Alat monitoring memainkan peran penting dalam memantau kesehatan aplikasi secara real-time. Dengan memantau metrik kunci, tim operasional dapat mengidentifikasi dan mengatasi masalah sebelum berdampak pada pengguna.
- Pemantauan Infrastruktur: Pantau penggunaan CPU, memori, disk I/O, dan metrik jaringan server. Alat seperti Prometheus dan Grafana dapat digunakan untuk memvisualisasikan data ini.
- Pemantauan Aplikasi: Pantau kinerja aplikasi, termasuk waktu respons, tingkat kesalahan, dan throughput. Gunakan alat seperti New Relic, Datadog, atau Sentry untuk memantau kinerja aplikasi.
- Pemantauan Basis Data: Pantau kinerja basis data, termasuk penggunaan sumber daya, waktu respons kueri, dan tingkat kesalahan. Gunakan alat khusus untuk basis data yang Anda gunakan, seperti MySQL Enterprise Monitor atau pgAdmin untuk PostgreSQL.
- Pemantauan Log: Kumpulkan dan analisis log aplikasi dan sistem untuk mengidentifikasi masalah dan tren. Gunakan alat seperti ELK Stack (Elasticsearch, Logstash, Kibana) atau Splunk untuk mengelola log.
- Alerting: Konfigurasikan alert untuk memberi tahu tim operasional jika ada metrik yang melebihi ambang batas yang telah ditentukan.
- Dashboard: Buat dashboard yang komprehensif untuk memvisualisasikan metrik kunci dan status aplikasi secara real-time.
Langkah-langkah Failover Manual
Meskipun sistem dirancang untuk failover otomatis, ada situasi di mana failover manual mungkin diperlukan. Memahami langkah-langkah yang terlibat sangat penting untuk memastikan transisi yang lancar dan meminimalkan downtime.
- Identifikasi Masalah: Identifikasi masalah yang memerlukan failover. Periksa log, dashboard, dan peringatan untuk menentukan akar penyebab masalah.
- Verifikasi Kesiapan Sumber Daya Cadangan: Pastikan sumber daya cadangan (server, basis data, dll.) siap untuk mengambil alih. Periksa status mereka dan pastikan mereka sinkron dengan data terbaru.
- Nonaktifkan Sumber Daya Utama: Nonaktifkan sumber daya utama yang bermasalah. Ini dapat melibatkan menghentikan layanan, mematikan server, atau memutus koneksi jaringan.
- Alihkan Lalu Lintas: Alihkan lalu lintas ke sumber daya cadangan. Ini dapat dilakukan dengan mengubah konfigurasi DNS, menggunakan load balancer, atau menggunakan mekanisme failover yang telah disiapkan.
- Verifikasi Operasi: Verifikasi bahwa aplikasi berfungsi dengan benar pada sumber daya cadangan. Periksa log, dashboard, dan lakukan pengujian sederhana untuk memastikan semuanya berjalan sesuai rencana.
- Pantau dan Perbaiki: Pantau kinerja aplikasi pada sumber daya cadangan. Perbaiki masalah yang mendasar pada sumber daya utama.
- Kembalikan ke Sumber Daya Utama (Opsional): Setelah sumber daya utama diperbaiki, Anda dapat mempertimbangkan untuk mengembalikan lalu lintas ke sana. Lakukan pengujian dan verifikasi sebelum melakukan transisi.
- Dokumentasi: Dokumentasikan semua langkah yang diambil selama proses failover, termasuk waktu, masalah yang dihadapi, dan solusi yang diterapkan.
Studi Kasus: Penerapan Nyata

Penerapan desain ketersediaan tinggi (high availability/HA) bukanlah sekadar konsep teoritis, melainkan strategi krusial yang terbukti memberikan dampak signifikan pada kinerja dan keberlangsungan bisnis. Banyak perusahaan telah berhasil meningkatkan uptime aplikasi mereka secara dramatis melalui implementasi HA yang tepat. Mari kita telaah beberapa studi kasus untuk memahami lebih dalam bagaimana desain HA diterapkan dan manfaat yang diraih.
Studi Kasus: E-Commerce Raksasa
Sebuah perusahaan e-commerce global yang melayani jutaan pelanggan setiap hari menghadapi tantangan serius terkait ketersediaan layanan. Periode downtime yang singkat sekalipun dapat menyebabkan kerugian finansial yang besar, merusak reputasi, dan mengurangi kepercayaan pelanggan. Perusahaan ini memutuskan untuk mengimplementasikan desain HA yang komprehensif untuk mengatasi masalah ini.
- Tantangan yang Dihadapi: Perusahaan menghadapi beberapa tantangan utama. Pertama, infrastruktur yang ada rentan terhadap kegagalan perangkat keras dan perangkat lunak. Kedua, lonjakan trafik yang tiba-tiba, terutama selama periode promosi besar-besaran, dapat menyebabkan kelebihan beban sistem. Ketiga, pemeliharaan dan pembaruan sistem secara rutin seringkali menyebabkan downtime.
- Solusi yang Diterapkan: Untuk mengatasi tantangan tersebut, perusahaan mengadopsi beberapa solusi HA.
- Redundansi: Mereka menerapkan redundansi pada semua lapisan infrastruktur, termasuk server, database, dan jaringan. Hal ini berarti memiliki salinan cadangan dari setiap komponen yang dapat mengambil alih secara otomatis jika terjadi kegagalan.
- Load Balancing: Load balancing digunakan untuk mendistribusikan lalu lintas ke beberapa server, memastikan tidak ada satu server pun yang kelebihan beban.
- Failover Otomatis: Sistem failover otomatis dikonfigurasi untuk mendeteksi kegagalan dan secara otomatis mengalihkan lalu lintas ke server cadangan.
- Monitoring Proaktif: Sistem monitoring yang canggih diimplementasikan untuk memantau kinerja sistem secara terus-menerus dan memberikan peringatan dini jika terjadi masalah.
- Pembaruan Bergulir: Pembaruan sistem dilakukan secara bergulir, sehingga hanya sebagian kecil dari sistem yang mengalami downtime pada satu waktu.
- Hasil yang Dicapai: Implementasi desain HA memberikan hasil yang luar biasa.
- Peningkatan Uptime: Uptime aplikasi meningkat secara signifikan, mendekati 99.99%.
- Peningkatan Kepuasan Pelanggan: Pelanggan mengalami lebih sedikit gangguan layanan, yang meningkatkan kepuasan dan loyalitas.
- Peningkatan Pendapatan: Minimnya downtime dan peningkatan kinerja menghasilkan peningkatan pendapatan.
- Pengurangan Biaya: Meskipun investasi awal cukup besar, biaya yang terkait dengan downtime dan pemulihan sistem berhasil dikurangi.
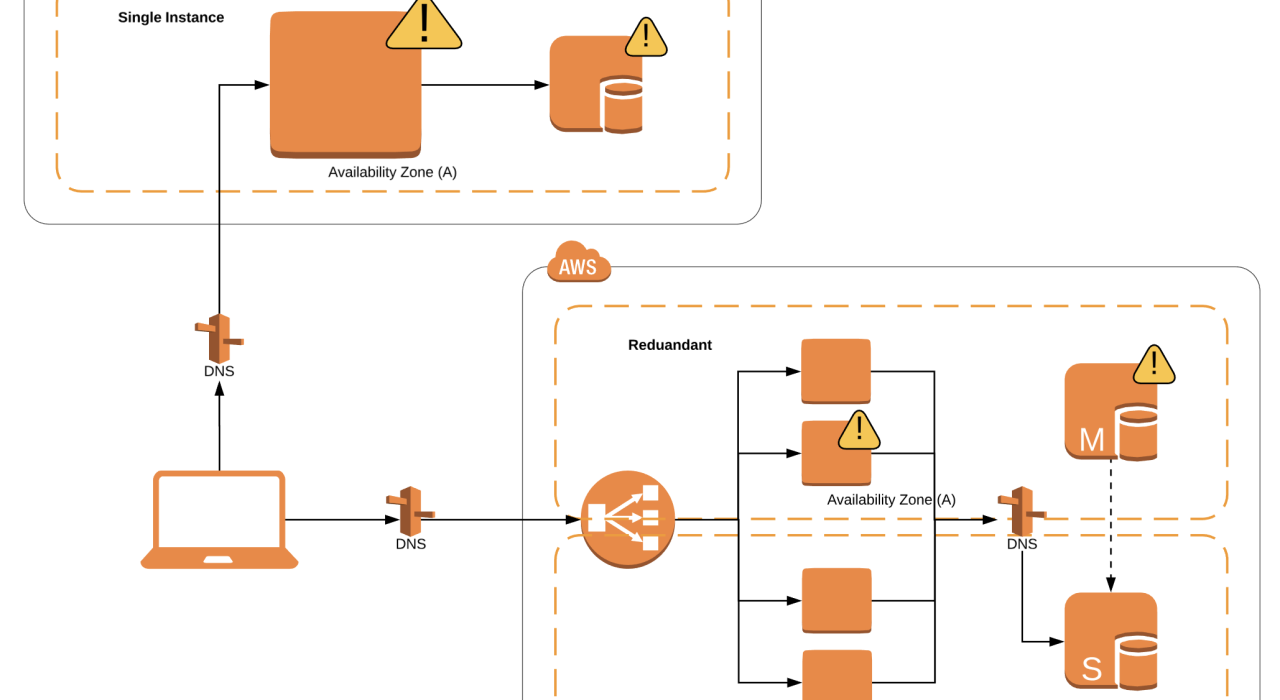
Ilustrasi Arsitektur Aplikasi
Berikut adalah deskripsi ilustrasi yang menggambarkan perubahan arsitektur aplikasi sebelum dan sesudah penerapan desain HA:
Sebelum Penerapan HA:
Arsitektur aplikasi sebelum penerapan HA digambarkan sebagai struktur sederhana. Terdapat satu set server web, satu database server, dan satu server aplikasi. Semuanya terhubung langsung melalui jaringan. Jika salah satu server mengalami masalah, seluruh aplikasi akan mengalami downtime. Tidak ada mekanisme failover atau load balancing.
Sesudah Penerapan HA:
Arsitektur aplikasi sesudah penerapan HA jauh lebih kompleks dan tangguh. Terdapat beberapa server web yang didistribusikan di beberapa lokasi, di belakang load balancer. Database server direplikasi ke beberapa server database, dengan sistem failover otomatis. Server aplikasi juga direplikasi, dengan load balancing untuk mendistribusikan lalu lintas. Semua komponen terhubung melalui jaringan yang redundan. Terdapat sistem monitoring yang memantau kinerja semua komponen secara real-time. Jika salah satu komponen mengalami kegagalan, sistem secara otomatis mengalihkan lalu lintas ke komponen cadangan tanpa gangguan.
Perbandingan Kinerja Aplikasi
Perbandingan kinerja aplikasi sebelum dan sesudah penerapan desain HA menunjukkan perbedaan yang signifikan.
| Parameter Kinerja | Sebelum HA | Sesudah HA |
|---|---|---|
| Uptime | 80% | 99.99% |
| Waktu Respons Aplikasi | Berfluktuasi, seringkali lambat saat beban tinggi | Konsisten, cepat, bahkan saat beban tinggi |
| Jumlah Transaksi yang Diproses | Terbatas, seringkali mengalami kegagalan saat beban tinggi | Meningkat secara signifikan, mampu menangani lonjakan trafik |
| Kepuasan Pelanggan | Rendah, banyak keluhan tentang downtime | Tinggi, sedikit keluhan tentang gangguan layanan |
Ringkasan Penutup
Merancang aplikasi dengan ketersediaan tinggi bukan hanya tentang teknologi, tetapi juga tentang komitmen terhadap keandalan dan kepuasan pelanggan. Dengan memahami prinsip-prinsip dasar, memilih teknologi yang tepat, dan menerapkan prosedur operasional yang efektif, Anda dapat menciptakan lingkungan digital yang tangguh dan selalu siap menghadapi tantangan. Investasi dalam desain ketersediaan tinggi adalah investasi dalam masa depan bisnis Anda, memastikan kelangsungan operasional dan memberikan keunggulan kompetitif di pasar.